Abstract
Solving complex real-world control tasks often takes multiple tries: if we fail at first, we reflect on what went wrong, and change our strategy accordingly to avoid making the same mistake. In robotics, Vision-Language-Action models (VLAs) offer a promising path towards solving complex control tasks, but lack the ability to contextually and dynamically readjust behavior when they fail to accomplish a task. In this work, we introduce Learning from Inference-Time Execution (LITEN), which connects a VLA low-level policy to a high-level VLM that conditions on past experiences by including them in-context, allowing it to learn the affordances and capabilities of the low-level VLA. Our approach iterates between a reasoning phase that generates and executes plans for the low-level VLA, and an assessment phase that reflects on the resulting execution and draws useful conclusions to be included in future reasoning contexts. Unlike similar approaches to self-refinement in non-robotics domains, LITEN must reflect on unstructured real-world robot trajectories (e.g., raw videos), which requires structured guiderails during assessment. Our experimental results demonstrate LITEN is able to effectively learn from past experience to generate plans that use high-affordance instructions to accomplish long-horizon tasks.
Learning from Inference-Time Execution (LITEN)
VLAs hold great promise for solving open-world robotics tasks, but are still quite limited when it comes to solving complex, long-horizon tasks. Two key limitations to current VLAs are that (1) they struggle to understand and perform multi-step instructions, and (2) they are "single-shot": VLAs won't adjust their behavior and re-try a task, or learn from previous attempts. In our work, we present Learning from Inference-Time Execution (LITEN), which addresses these limitations by treating the VLA as a low-level controller and coupling it with a high-level VLM, which can act as a "planner" and break down a complex task into a sequence of simpler instructions for the VLA to accomplish step-by-step. More importantly, however, LITEN provides a novel means of including past experiences in-context for the VLM, so it can learn from successes and failures it made in the past to better inform future plans for the VLA.
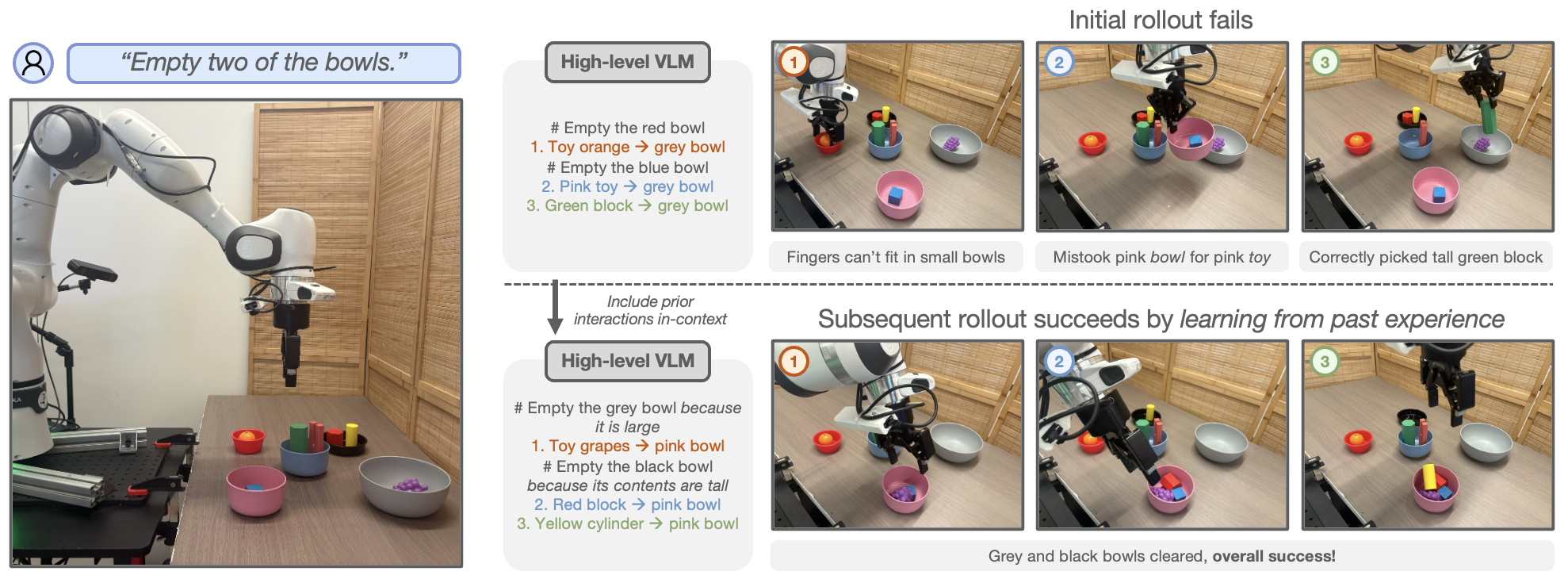
This illustration shows an example of how LITEN works. At first, the VLM is asked to generate a plan for the VLA, but doesn't know the VLAs capabilities, and has a limited understanding of the dynamics of the physical environment it will be acting in. As such, the instructions that the VLM initially prescribes for the VLM are incorrectly executed, which leads to a failure on the overall task. LITEN takes the trajectories of this failed attempt, and employs a VLM-as-a-judge to distill meaningful information from its failure. LITEN includes these takeaways in-context for future attempts, and is eventually able to generate a successful plan for the overall task.
The LITEN Procedure
The LITEN procedure alternates between two phases: reasoning and assessment. In the reasoning phase, LITEN has a VLM generate a plan for the VLA based on the overall task and past experiences. In the assessment phase, LITEN collects the previous attempt (as video recordings) and asks a VLM judge to determine whether each subtask in the plan failed or succeeded, what the robot did instead in the case of failure, and what factors of the environment or the VLA could have led to a failed execution.
Example VLM Judge Assessments

Here, we provide a few condensed examples of the VLM judge's assessments of subtasks that were executed by our VLA. We provide more information in our prompts to help the VLM judge generate useful feedback. The VLM judge produces more verbose output than what we illustrate above. Full examples are available in our codebase, and more condensed examples are provided down below.
Results
We evaluate LITEN in three complex, long-horizon tabletop manipulation tasks, using the DROID hardware setup. We use the π0.5-DROID VLA, which is available and open-source. We present videos showing LITEN's first attempt at solving the task, followed by a successful attempt that occurred after some number of iterations.
Task 1: Stacking three objects atop one another
Task 2: Emptying two of the bowls on the table by moving objects between bowls
Task 3: Moving objects onto other objects so that only three objects are in contact with the table
Our results show that LITEN learns to solve our experimental over successive attempts, outperforming baseline approaches to VLM self-refinement that are not tailored to robot learning.
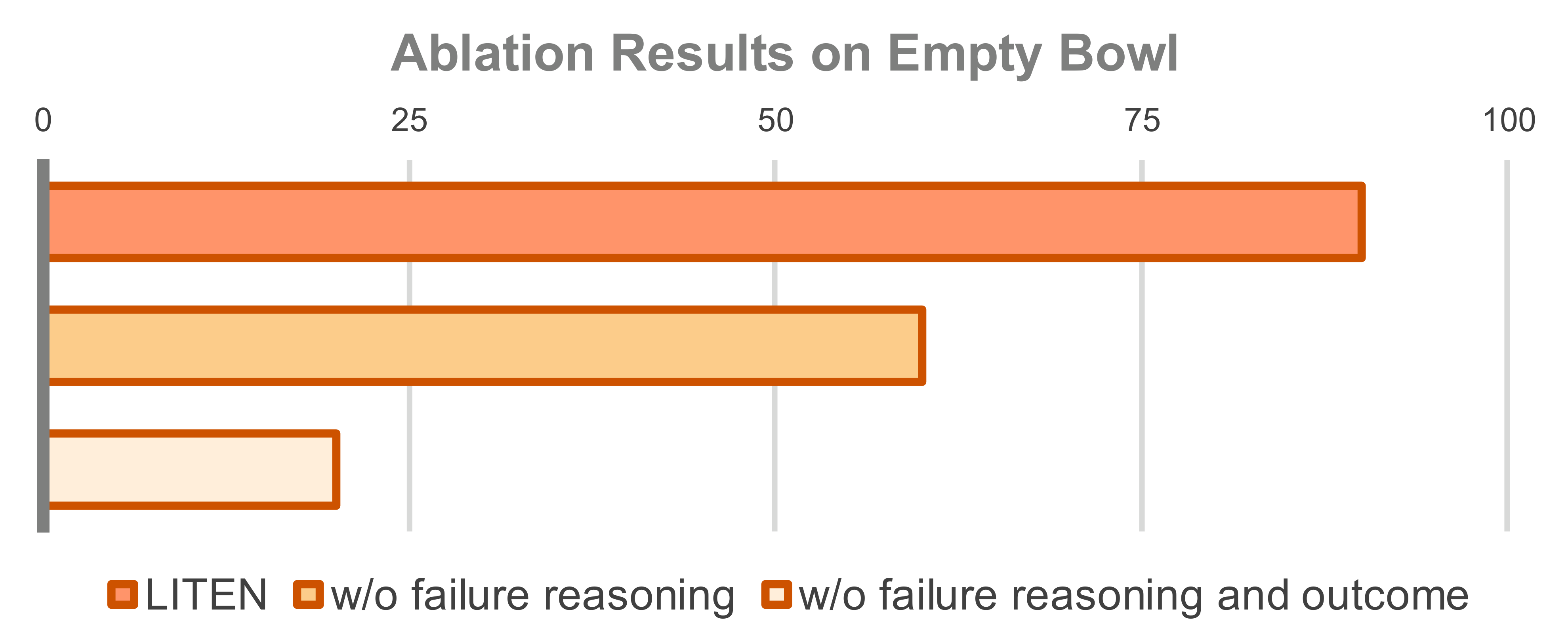
We also perform an ablation study on LITEN where we take out specific components of the assessment phase, such as asking the VLM judge to speculate about why the VLA-controlled robot may have failed to accomplish a subtask. Somewhat unsurprisingly, we found that it's important to structure the assessment phase in a way that clearly identifies possible causes of failure and means for improvement for future use by the VLM.
Illustrated Attempt Sequences from LITEN
We provide a few more condensed illustrative examples, showing how LITEN learns over multiple attempts to eventually solve tasks:
Move off Table
Here, LITEN learns to place objects on top of each other by learning which objects in the scene will properly balance on others.
Empty Bowls
In this task, LITEN empties bowls by learning which bowls contain graspable objects (either due to depth or size), and which bowl the VLA is predilected towards targeting.
Stacking
Here, LITEN must create a stack of three objects by learning both which objects can be more easily stacked (such as smaller objects atop large, flat ones), and which objects the VLA is biased towards.
